向量数据库
AI
向量数据库
🧠 一、什么是向量数据库(Vector Database)
向量数据库是一种专门用于存储、索引和检索“向量(vector)”的数据库。
简单来说,它不是存储传统的结构化数据(如表格、字段),而是存储高维向量表示(embedding)。
举个例子:
内容类型 原始数据 向量化(Embedding) 文本 “苹果公司” [0.12, 0.85, -0.33, ...] 图片 一张猫的照片 [0.44, 0.91, 0.02, ...] 音频 一段语音 [0.08, 0.65, 0.77, ...] 向量数据库的任务是:
给定一个向量,快速找到与之“最相似”的向量。
⚙️ 二、技术原理
向量数据库的核心在于 相似度搜索(Similarity Search),主要原理如下:
1️⃣ 向量化(Embedding)
首先,原始数据(文本、图片、视频等)会通过模型(如 OpenAI Embedding、CLIP、BERT 等)转成向量。
这个过程叫 向量化(Embedding)。
2️⃣ 向量存储
这些高维向量(通常是几百到几千维)被存进数据库。
普通关系型数据库不擅长处理高维数据,因此需要专门的存储结构和索引。
3️⃣ 相似度度量
常见的相似度算法包括:
- 余弦相似度(Cosine Similarity)
- 欧氏距离(L2 Distance)
- 内积(Dot Product)
4️⃣ 近似最近邻搜索(ANN, Approximate Nearest Neighbor)
直接计算所有向量的距离开销太大(百万甚至上亿级向量),
所以使用 ANN 技术加速,比如:
- HNSW(Hierarchical Navigable Small World)
- IVF(Inverted File Index)
- PQ(Product Quantization)
- Faiss、ScaNN、Annoy 等算法
这些算法可在数百万向量中,在毫秒级找到最相似的前 K 条记录。
🎯 三、向量数据库的主要用途
应用场景 说明 RAG(检索增强生成) 大模型问答中,通过检索知识库中与问题语义相似的内容,再让模型生成答案。 语义搜索 不再依赖关键词匹配,而是通过语义相似度找到结果。 推荐系统 用户与内容都向量化,通过相似度推荐相似物品。 图像/音频/视频检索 通过内容相似度找到相似图片、音频或视频片段。 多模态检索 文本、图片、语音向量统一表示,实现跨模态检索。 🧩 四、常见向量数据库对比
名称 语言/部署 特点 优点 缺点 Pinecone SaaS 云服务 全托管,自动扩展 稳定、省心、RAG集成好 付费且封闭源代码 Milvus 开源(Zilliz 出品) 支持上亿向量、HNSW/PQ等索引 企业级性能、生态强 部署稍复杂 Weaviate 开源 + 云 GraphQL 接口,支持多模态 支持混合搜索(keyword+vector) 内存消耗较大 FAISS Facebook 开源库(C++/Python) 高性能 ANN 算法库 速度极快,离线可用 不是完整数据库(无持久化/集群) Qdrant Rust 开源 高性能、支持过滤、HNSW 性能强、易集成、Docker方便 生态略小 Chroma Python 本地库 面向 LLM 开发(LangChain内置) 开发快、轻量 不适合大规模生产 Vespa Yahoo! 开源 搜索引擎与向量融合 混合检索强大 配置复杂 Redis Vector Redis 模块 在 Redis 基础上加向量索引 易部署、低延迟 功能有限、不适合超大数据量 🧠 五、工作流程示意图
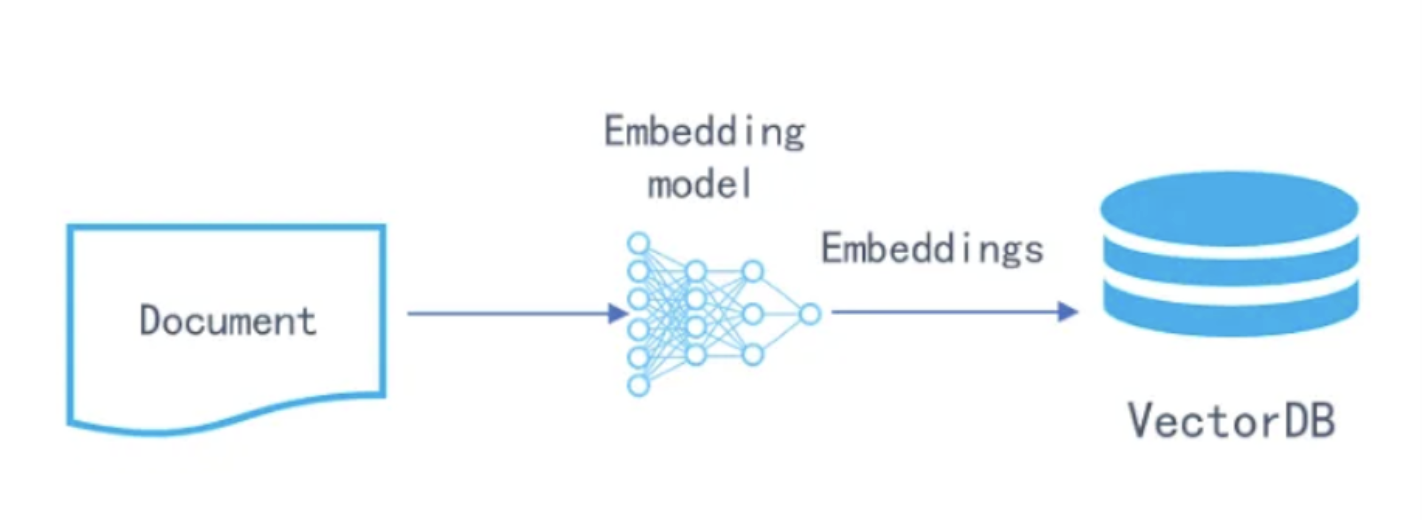
🚀 六、总结
分类 内容 定义 存储与检索高维向量的数据库 核心技术 向量化 + ANN(近似最近邻搜索) 典型用途 RAG、语义搜索、推荐、相似内容检索 主流产品 Pinecone, Milvus, Weaviate, FAISS, Qdrant, Chroma 趋势 与LLM深度结合,支持多模态与混合检索

超锅
野生全栈程序员,8年搬砖经验,熟悉 Golang/Java/Python/NodeJS/React/Android等单词拼写