什么是RAG?RAG的主要流程详谈
AI
RAG
人工智能
什么是 RAG(Retrieval-Augmented Generation)?
RAG = 先用“检索器”快速找出与问题最相关的外部知识片段,再把“片段+问题”一起喂给“生成器”,让大模型在最新、最专的知识边界内作答,从而降低幻觉、提升时效与可解释性。
详细分步解析
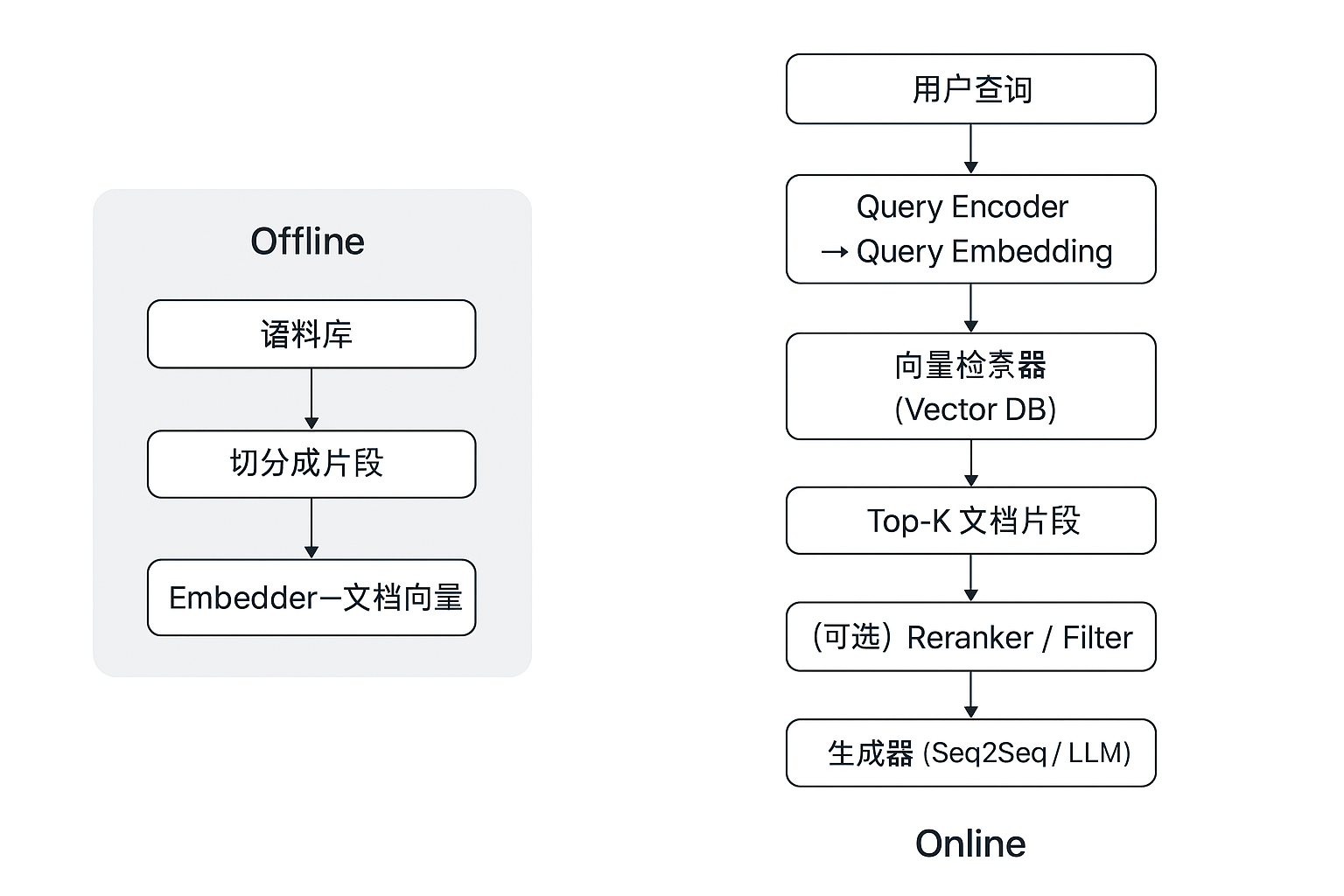
1) 数据准备与索引(离线)
- 语料切分(chunking):把长文档切成合适长度的段(例如 100–500 tokens),太短丢失上下文,太长检索效率低。
- 嵌入模型(embedder):常用 sentence-transformers、DPR 类模型或任意能产生高质量语义向量的模型。
- 向量索引/DB:FAISS、Milvus、Pinecone、Weaviate 等。FAISS 是最常见的开源高性能库。
- 元数据存储:每个向量对应原文片段 + 源信息(文档 id、段落偏移、时间戳等),用于返回引用/溯源。
2) 检索器(在线)
- 编码查询:用同一或兼容的 embedder 将查询转成向量。
- 检索 top-k:通常 k 在 3–50 之间,取决于生成器的上下文容量与延迟预算。
- 混合检索:可以先用 BM25(稀疏)快速过滤,再用向量检索排序(稠密);或同时使用二者融合以提高召回与精准度。
3) 可选重排(reranking)
- Lightweight:基于相似度阈值或规则过滤无关片段。
- Cross-encoder:用跨编码器(cross-encoder)对 query+passage 配对进行逐对打分、再选 top-m 作最终输入(代价高但效果好)。
4) 生成器(conditioning & fusion)
- 主要变体(来自 RAG 论文):
- RAG-Sequence:为整条生成序列条件于同一组检索到的 passages。
- RAG-Token:允许每生成一个 token 时利用不同的检索结果(更灵活但复杂)。
- 原始论文比较了这些方案并在多个知识型任务上给出优势证据。
- Fusion 方法:
- Concat(简单拼接):把 passages 串联到 prompt 前/后;适合小 k。
- Fusion-in-Decoder (FiD):对每个 passage 单独编码,然后在 decoder 端融合它们的表示,被证明对问答等任务很有效
5) 输出与溯源
- 返回生成文本同时附上“证据片段/来源链接/置信度”,方便人工校验和合规。RAG 的一个重要目的就是让知识可更新且有追溯路径。

超锅
野生全栈程序员,8年搬砖经验,熟悉 Golang/Java/Python/NodeJS/React/Android等单词拼写